| Oracle TimesTen In-Memory Databaseオペレーション・ガイド
リリース6.0 B25767-02 |
|


 前へ |
 次へ |
準備されたSELECT文、UPDATE文、DELETE文、INSERT SELECT文またはCREATE VIEW文の計画を表示するには、次のようなステップが必要になります。
最初の2つのステップが完了すると、コマンドの計画がPLAN表に格納されます。格納された計画は、コマンドの再準備が実行されるたびに自動的に更新されます。この再準備は、あまり頻繁には実行されません。ただし、文に記述された表が変更された場合、索引が作成または破棄された場合、または統計が更新されたときにコマンドが無効になるようにアプリケーションで設定している場合は、PLAN表を再度読み取って、コマンドの計画が変更されていないかどうか確認するようにしてください。
計画を表示するには、GenPlanフラグを指定して組込みプロシージャttOptSetFlagをコールしておく必要があります。このコールによって、それ以降にODBC SQLPrepare関数またはJDBC Connection.prepareStatementメソッドのコールがトランザクションにあれば、そのすべてのコールから得られた計画が現在のSYS.PLAN表に保存されるようになります。
SYS.PLAN表に格納できる計画は1つのみです。このため、ODBC SQLPrepare関数またはJDBC Connection.prepareStatementメソッドがコールされるたびに、その時点で表に格納されていた計画は上書きされます。
コマンドの準備時にgenPlanフラグが設定されていた場合は、同じフラグが設定されて再度コンパイルされます。したがって、別の問合せのための計画がSYS.PLAN表内にある場合でも、計画は作成されます。
ttIsqlユーティリティを使用すると、テスト目的で問合せやオプティマイザのヒントを試してみることができます。オプティマイザの計画を表示するには、次のコマンドを発行します。
計画の生成を有効にしてコマンドの準備が終了すると、SYS.PLAN表の1つ以上の行にコマンドの計画が格納されます。その行数は、コマンドがどの程度複雑かによって変わります。それぞれの行には、列が7つあります。詳細は、『Oracle TimesTen In-Memory Database APIおよびSQLリファレンス・ガイド』のシステム表とレプリケーション表に関する項を参照してください。
次の問合せを準備するとします。
SELECT COUNT(*) FROM T1, T2, T3 WHERE T3.B/T1.B > 1 AND T2.B <> 0 AND T1.A = -T2.A AND T2.A = T3.A次の表に示すとおり、オプティマイザによって次の5つのSYS.PLAN行が生成されます。各行は、計画の1つのステップで、問合せの実行時に実行される処理を示します。
次に、SYS.PLAN表の各列の詳細について説明します。例9.1全体を使用して説明します。
SYS.PLAN表には、7つの列があります。この項では、その内容について説明します。
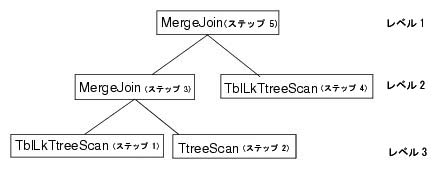
処理の順序を示します。この例では、表ロックTツリー・スキャンを使用しています。順序は次のとおりです。
処理を表す結合ツリー図での操作の位置を示します。前述の例の結合ツリーは、次のようになります。
実行される処理のタイプを示します。このフィールドの値と表スキャンのタイプの詳細は、『Oracle TimesTen In-Memory Database APIおよびSQLリファレンス・ガイド』のシステム表とレプリケーション表に関する章のSYS.PLANを参照してください。
オプティマイザが実行した処理内容がすべてユーザーに表示されるわけではありません。パフォーマンスの解析にとって重要な処理のみがSYS.PLAN表に表示されます。TblLkは、シリアライズ可能分離モードまたはコミット読取り分離モードでの実行時に使用可能なオプティマイザ・ヒントです。表ロックは、準備時に行ロックが無効になっている場合にのみスキャン時に使用されます。
スキャンされる表を示します。この列は、処理がスキャン(前述の最初の5つの処理の1つ)の場合にのみ使用されます。それ以外の場合、この列はNULLです。
使用される索引を示します。この列は、処理が、既存の索引を使用する(ハッシュまたはTツリー・スキャンを使用する)索引スキャンの場合にのみ使用されます。それ以外の場合、この列はNULLです。スキャンが降順(小から大ではなく、大から小)の場合、Tツリー索引の名前に「(D)」が付きます。
処理に条件が含まれる場合に、その条件を示します。条件が使用されるのは、索引スキャンとMergeJoinの処理のみです。
Tツリー・スキャンの場合、この列がNULL(条件がない状態)になることがあります。オプティマイザは、表スキャンよりもTツリー・スキャンを優先します。これは、フィルタリングの他に、次のような2つの便利な特徴があるためです。
例9.1では、ソートにTツリー・スキャンを使用しています。このスキャンでは、条件は評価されません。
条件文字列は、1,024文字に制限されています。
処理の実行時に適用される他の条件を示します。これらの条件は、直接的にスキャンまたは結合で使用されることはありませんが、スキャンまたは結合によって戻された各行で評価されます。
たとえば、前述の例に対して生成された計画のステップ2では、Tツリー・スキャンが表T2で実行されます。そのスキャンの実行時には、条件T2.B <> 0も評価されます。同様に、最後のマージ結合が終了すると、条件T3.B / T1.B > 1の評価が可能になります。